Hi,
When the SciChart library if fed a dataset with more datapoints along the X-axis than physical pixels, what happens with those points that it can not physically render? For reference our Y-axis is a floating point value and the X-axis is a time series.
Does it discard excess datapoints (what defines which to be discarded?), or does it average those datapoints together to give one resulting datapoint that it can actually physically display?
Essentially, we are trying to work out what form of filtering is going on to give a resulting display output.
Thanks,
Simon.
- Simon Chambers asked 9 years ago
- last edited 9 years ago
- You must login to post comments
Hi Simon,
While I can’t give away the exact specifics of the internals of SciChart, I can tell you what sort of techniques we employ to reduce the drawing burden. As you’ve rightly pointed out, there are many cases where there are more data-points than there are physical pixels on the screen. Drawing them all would be wasteful!
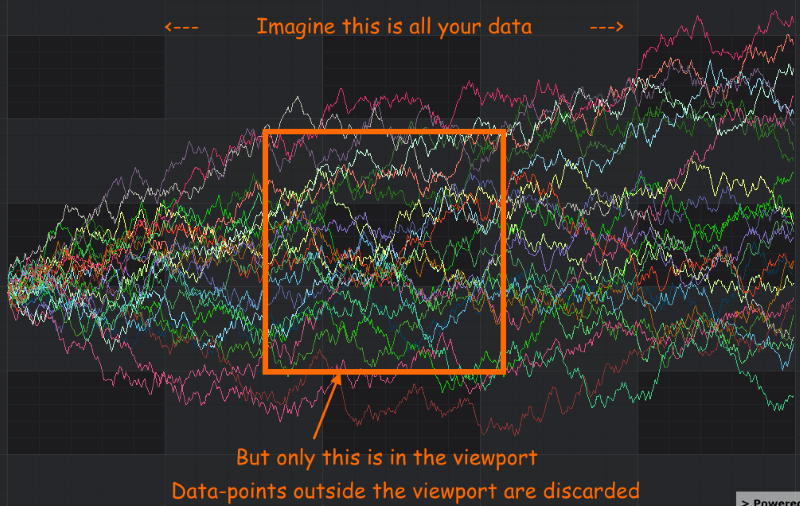
Virtualization / Viewport Clipping
Firstly, SciChart employs clipping. In game-programming language, this is called viewport culling. In WPF language, its called virtualization. In plain English, it simply means that points outside of the viewport are discarded.
Resampling
The second technique SciChart employs is Resampling (see our article What are ResamplingModes). There are a number of resampling algorithms within SciChart. The default mode is ResamplingMode.Auto, which detects some properties about your data and chosen renderableseries and applies the fastest, lossless resampling algorithm to reduce the data-set.
You can test out our ResamplingModes in the Performance Demo.
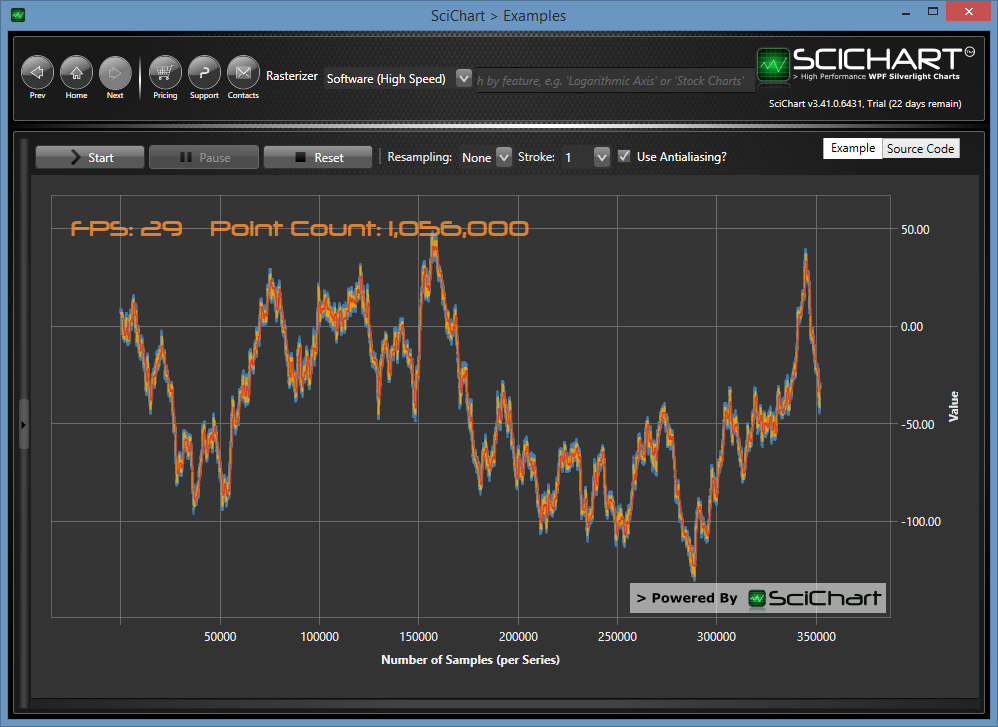
Above: ResamplingMode.None
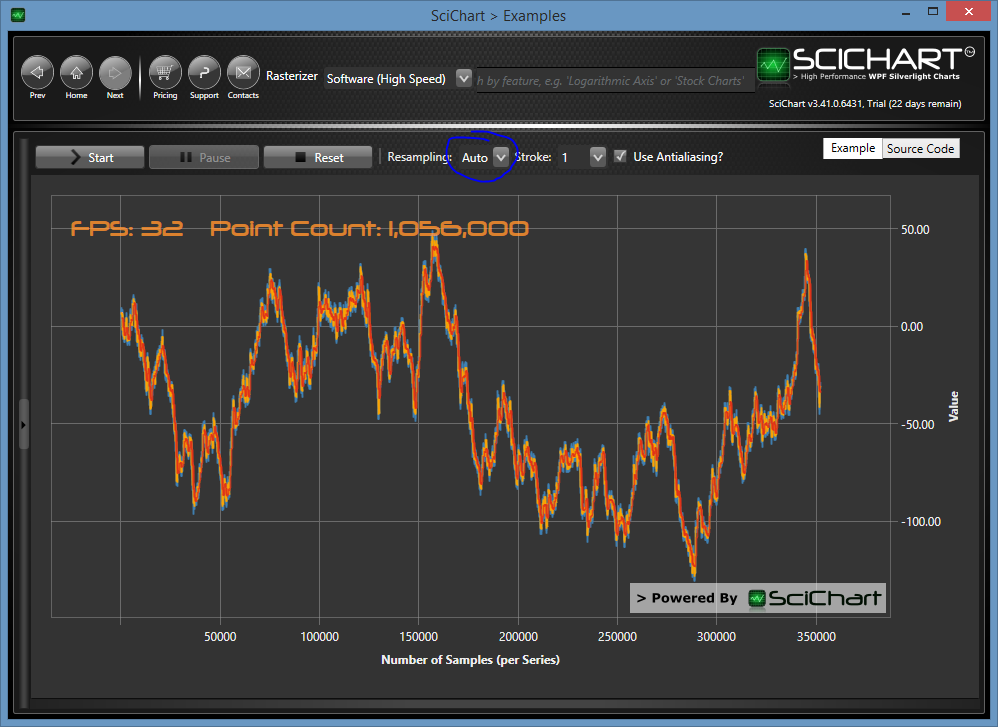
Above: ResamplingMode.Auto
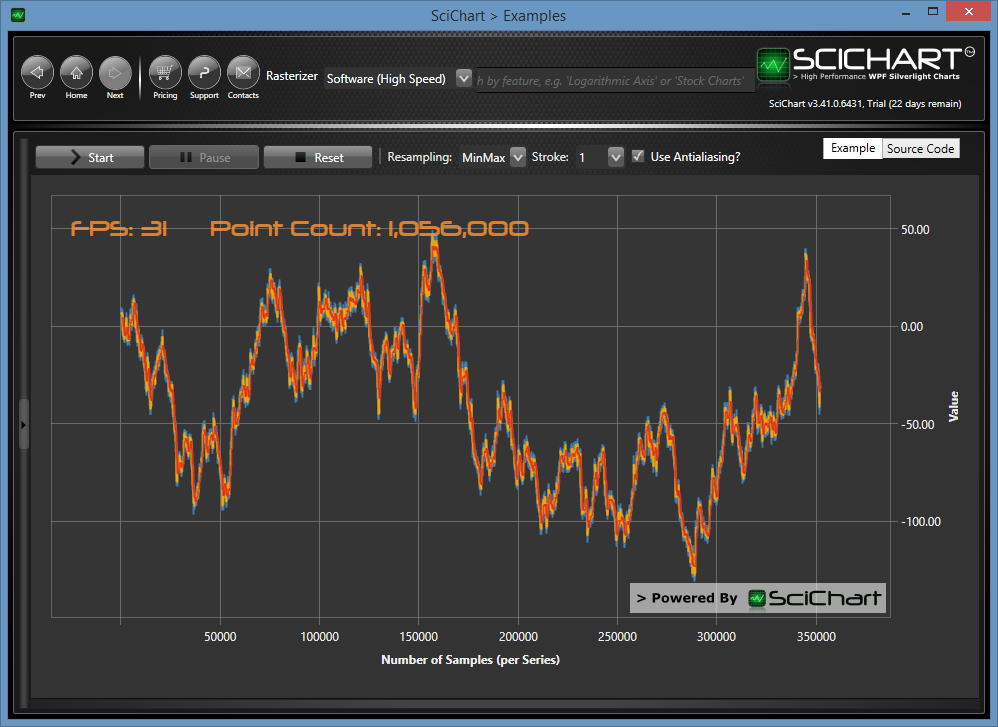
Above: ResamplingMode.MinMax
Resampling Performance
Assuming your data is a time-series (ascends in X-value) then it is possible to resample 10,000,000 points to approx 8,000 in ~100ms on a pretty standard workstation. This makes many millions of points possible with SciChart.
Is Resampling unsuitable for any chart types?
-
Yes, Scatter series cannot be resampled, and the default
ResamplingMode for these series is None. There is an experimental ResamplingMode.Cluster2D but it isn’t as fast as MinMax. -
Series with unsorted data (data is unsorted in X) cannot be
resampled. ResamplingMode.Auto will detect this and apply
ResamplingMode.None -
Charts with Logarithmic X-Axis cannot be accurately (and quickly) resampled. Please exercise caution when using charts with a Log XAxis and we recommend choosing ResamplingMode.None.
- Andrew Burnett-Thompson answered 9 years ago
- You must login to post comments
Another article which may be useful to you is http://www.scichart.com/insane-wpf-scatter-chart-performance-with-parallel-rendering.
Here we demonstrate a clustered culling algorithm for scatter points. Again the intention is to be lossless (or near lossless in this case).
We don’t want to lose data as our customers are in the scientific / medical / financial sectors. At the same time we don’t want to overdraw as this is wasteful on resources. The solutions we’ve chosen are hopefully the best all-round compromise!
Best regards,
Andrew
- Andrew Burnett-Thompson answered 9 years ago
- You must login to post comments
Please login first to submit.
